2018-07-12 11:19:51 464浏览
在目前相信大多数IT开发人员对于人工智能+大数据并不陌生,使用的场景也越来越广,日常开发中前端同学也逐渐接触了更多与大数据开发相关需求,导致越来越多IT开发程序员想要了解或参加大数据培训知识,下面是扣丁学堂老师整理一下关于大数据入门之Hadoop基础学习介绍。
Map的输出是Reduce的输入,Reduce的输入是Map的集合

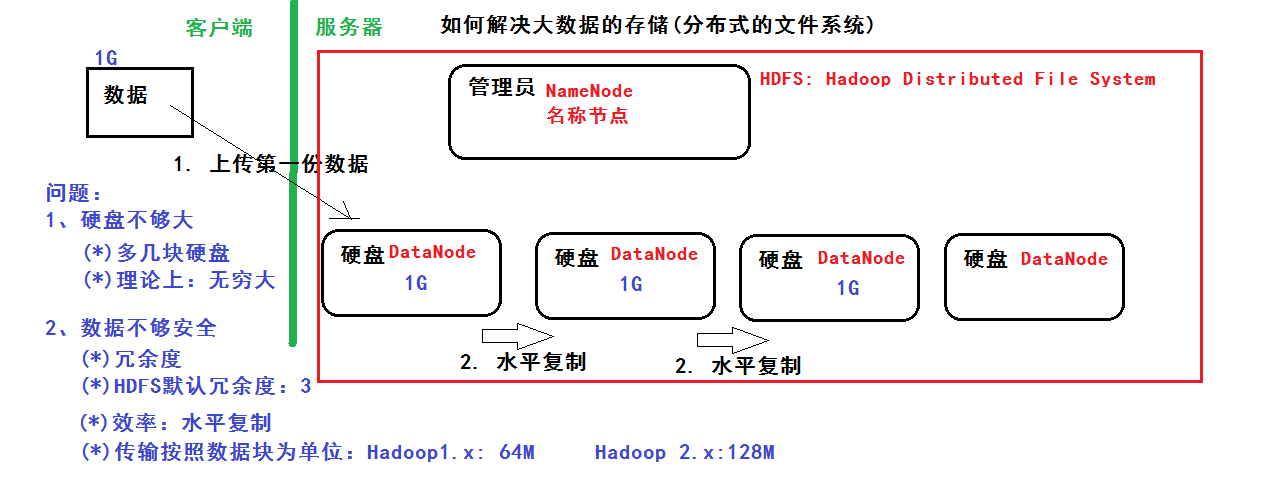
核心思想是:利用空间换效率

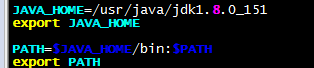
tar-zxvfhadoop-3.0.0.tar.gz-C/usr/local/ mvhadoop-3.0.0/hadoop

<!--配置冗余度为1--> <property> <name>dfs.replication</name> <value>1</value> </property> <!--配置权限检查为false--> <property> <name>dfs.permissions</name> <value>false</value> </property> 修改core-site.xml <!--配置HDFS的NameNode--> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.56.102:9000</value> </property> <!--配置DataNode保存数据的位置--> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property>
<!--配置MR运行的框架--> <property> <name>mapreduce.framework.name</name> <value>yar</value> </property> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.map.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.reduce.env</name> <value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value> </property> <property> <name>mapreduce.application.classpath</name> <value> /usr/local/hadoop/etc/hadoop, /usr/local/hadoop/share/hadoop/common/*, /usr/local/hadoop/share/hadoop/common/lib/*, /usr/local/hadoop/share/hadoop/hdfs/*, /usr/local/hadoop/share/hadoop/hdfs/lib/*, /usr/local/hadoop/share/hadoop/mapreduce/*, /usr/local/hadoop/share/hadoop/mapreduce/lib/*, /usr/local/hadoop/share/hadoop/yarn/*, /usr/local/hadoop/share/hadoop/yarn/lib/*, </value> </property>
<!--配置ResourceManager地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>192.168.56.102</value> </property> <!--配置NodeManager执行任务的方式--> <property> <name>yarn.nodemanager.aux-service</name> <value>mapreduce_shuffle</value> </property>
hdfsnamenode-format
start-all.sh
(*)命令行 (*)JavaApi (*)WEBConsole
Hadoop是基于Java语言的,前端日常开发是用的PHP,在使用、查找错误时还是蛮吃力的。工作之余还是需要多补充点其它语言的相关知识,想要了解更多内容的小伙伴可以登录扣丁学堂官网咨询,不仅有专业的老师和与时俱进的课程体系,还有大量的大数据视频教程供学员观看学习哦。扣丁学堂大数据学习群:209080834。

【关注微信公众号获取更多学习资料】


全国免费咨询热线
邮箱:codingke@1000phone.com
官方群:148715490
 15311698296
15311698296







